 技术好学屋
技术好学屋这是隐藏您的 (Python) 机器人不被检测的 12 种最佳方法的列表(不仅适用于 Selenium 和 Python BTW)(更新于 2021 年 6 月)
许多网站会使用 Captchas、FingerprintJS、Imperva 或他们自己的类似工具来阻止您的网络抓取/自动化,因为这会给网站的服务器带来不必要的负载,并增加维护网站的成本,而不会回馈任何价值。企业希望利用其资源为客户提供服务,而不是为那些只需要其数据的人提供服务。
这就是为什么他们跟踪不规则的浏览活动以阻止您的网络抓取工作。但是您不会轻易放弃,对吗?😉 这就是为什么我列出了 10 件事,您可以使用 Selenium 隐藏您的自动化并使其无法检测并看起来像真人。
1. 删除 Navigator.Webdriver 标志
Navigator.Webdriver Flag 表示浏览器是否由 Selenium 等自动化工具控制,也是您在使用 Selenium 和 Chrome 时收到的Chrome 正在由自动化测试软件控制通知栏的来源。
它旨在用作网站实现使用自动化工具的标准方式。然后,该网站可以运行替代代码来代替普通用户运行的代码——例如阻止脚本。
true当 Selenium 控制浏览器时,标志设置为。但是,通过使用基本的分析工具,每个网站都会看到并确定您使用的是自动浏览器。
它通常设置为true在--enable-automation、--headless flag或--remote-debugging-portChrome 中启用时。
对于 Firefox ,必须设置marionette.enabledFlag 或。--marionette
网站上的分析工具通常看起来像这样:
var isAutomated = navigator.webdriver;
if(isAutomated){
blockAccess();
} 但是由于检查布尔值非常简单,因此使用以下适用于 Chrome WebDriver 和 Firefox/Gecko WebDriver 的 Python 代码也很容易在运行时将其删除:
#Open Browser
option = webdriver.ChromeOptions()
browser = webdriver.Chrome(executable_path='chromedriver.exe',options=option)
#Remove navigator.webdriver Flag using JavaScript
browser.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")或者更好但仅在使用 Google Chrome 时有效。在设置之前移除标志。这样即使 Chrome 也不会知道您正在使用 Selenium:
option = webdriver.ChromeOptions()
#Removes navigator.webdriver flag
# For older ChromeDriver under version 79.0.3945.16
option.add_experimental_option("excludeSwitches", ["enable-automation"])
option.add_experimental_option('useAutomationExtension', False)
#For ChromeDriver version 79.0.3945.16 or over
option.add_argument('--disable-blink-features=AutomationControlled')
#Open Browser
browser = webdriver.Chrome(executable_path='chromedriver.exe',options=option)2. 混淆浏览器驱动程序 EXE 的 JavaScript
即使我说的是 EXE,如果您使用的是 Linux 或 Mac 🙃,这也适用于您。
专家提示
在撰写本文时,这一点仅适用于您使用 ChromeDriver 的情况。
如果您使用文本编辑器打开您的 ChromeDriver 并转到大约第 4000+ 行,您会发现一些将在您使用 Selenium 时运行的 JavaScript。
这就是为什么FingerprintJS、Imperva(前 Distil Networks)或 Google 的 Captcha 等机器人检测软件会查找此 JavaScript 代码的原因。
但幸运的是,您可以直接在可执行文件中编辑此 JavaScript – 只需将变量名称更改为相同长度的变量名称(否则 Selenium 将崩溃)。
如果您使用的是 ChromeDriver,最重要的变量可能是$cdc_asdjflasutopfhvcZLmcfl_. 因此,将紧接着的整个部分替换为另一个长度完全相同$的字符串。这是大多数检测器正在搜索的变量。完成后,许多大门已经向你敞开。
更具体地说:
- 使用文本编辑器打开 chromedriver.exe 。我会推荐 Notepad++,您只需右键单击 .exe 并选择:使用 Notepad++ 编辑
- 使用Ctrl+F搜索
$cdc_asdjflasutopfhvcZLmcfl_. 它在我当前的 Chrome 驱动程序中位于第 24816 行,但在您的驱动程序中可能位于不同的行。 - 将 之后的所有内容替换为长度相同
$的随机内容。例如(只需在键盘上敲一下,确保新字符串的长度相同)$btlhsaxJbTXmBATUDvTRhvcZLm_ - 按Ctrl+S保存。从现在开始,使用这个可执行文件作为你的驱动程序。
3. 更改分辨率、用户代理和其他细节
网站检测您的方法之一是使用您的监视器分辨率、用户代理和其他详细信息创建浏览器指纹,然后检查您是否发出了真人永远无法发出的异常数量的请求,或者应用其他启发式方法来检测你是否是机器人。
因此,通过使用 Following Python Code,您可以轻松更改它们:
#Change Browser Options
option = webdriver.ChromeOptions()
option.add_argument("window-size=1280,800")
option.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36")
#Open Browser
browser = webdriver.Chrome(executable_path='chromedriver.exe',options=option)你的目标应该是尽可能平均——因为你越独特,你就越容易被追踪。例如:使用高分辨率屏幕但使用过时的 User-Agent 会让你变得非常独特。
您可以查看AmIUnique.org,在那里您可以了解您的浏览器指纹是否是独一无二的。
为什么要努力做到平均?假设您使用独特的解决方案/用户代理设置在 1 分钟内发出 1000 个请求。这将很快被标记,因为一个人永远不可能在那个时间范围内访问那么多页面。
但是,如果您的解决方案/用户代理设置被 1000 人使用,每个人在 1 分钟内发出 1 个请求,那么您额外的 1000 个请求将意味着每个用户平均每分钟发出 2 个请求。这对人类来说是现实的。
但是在更改您的显示器分辨率、用户代理和其他细节时,您不应该忘记一致性。如果您使用的是 ChromeDriver,您应该使用 Chrome 用户代理,因为网站可以通过执行像这样的 JavaScript 挑战来了解您正在使用的真实浏览器
eval.toString().length以下浏览器将返回以下值:
- Firefox: 37
- Safari: 37
- Chrome: 33
- Internet Explorer: 39
因此,如果浏览器在其用户代理中伪装成 Firefox 但测试返回 33,则您可能会被标记为机器人。
同样的想法也适用于操作系统的一致性。使用以下代码,网站可以找出您真正使用的操作系统:
navigator.platform这些是为每个操作系统返回的值:
- Windows:Win32 或 Win64
- Android:Linux armv71 或 Linux i686
- iOS:iPhone 或 iPad
- FreeBSD:FreeBSD amd64 或 FreeBSD i386
- MacOS:MacIntel
- Linux:Linux i686 或 Linux x86_64
4. 逼真的页面流和避免陷阱
示例:真实用户在单击登录之前必须先访问主页,因为通常他们不知道登录页面的 URL。
这就是为什么有些网站会在您访问某个页面时设置 cookie,然后当您发出进一步请求时,它们会检查 cookie 是否存在。他们还可以跟踪页面流量并寻找模式以确定请求是否来自真人
因此,为避免被发现,请让您的机器人遵循您必须遵循的步骤。它会减慢你的机器人速度,但这比被阻止要好😶。
此外,还可能存在不可见链接等陷阱。例如,如果您访问站点 robots.txt 中不允许的页面,该站点可能会将您标记为机器人,因为这些通常是从未链接到的页面,因此您必须使用 URL 直接访问它。
5. 使用代理更改您的 IP 地址
抓取数千页的最佳方法是将其分发到具有不同详细信息的多台机器上。
但是由于不同的机器太贵了,为什么不像我在第 3 点“更改分辨率、用户代理和其他详细信息”中所说的那样更改所有识别详细信息和您的 IP 地址。
示例:就像我已经说过的。1000 个请求对一个人来说太多了。
但是 100 个请求分配给 100 个“人”(由不同的 IP 和指纹组成的身份)只会是每个用户 10 个请求。
要使用代理更改 Selenium 中的 IP 地址,您可以使用以下 Python 代码:
#Add Proxy
option = webdriver.ChromeOptions()
option.add_argument('proxy-server=106.122.8.54:3128')
#Open Browser
browser = webdriver.Chrome(executable_path='chromedriver.exe',options=option)互联网上有大量免费代理,但它们也可能被大量其他已标记的机器人使用 – 所以现在 IP 也被标记了。
这称为IP 信誉。IP 历史记录中的 IP 信誉因素、IP 的访问次数,或者它是否是已知的公共代理/Tor 代理。
这就是为什么您自己制作或购买私人代理的私人代理可以派上用场的原因——但这绝对不是所有抓取项目的必要条件。
如果您的目标网站具有非常具体的 IP 要求(例如,许多澳大利亚杂货网站只允许澳大利亚 IP),或者如果您想要抓取大量数据– 特别是在短时间内。
附加到物理位置的住宅 oxylabs 代理看起来更真实和合法,帮助您最大限度地减少 IP 禁令和验证码的数量 – 但在某些情况下,您只需要大量高速 IP 而不管机器人检测的质量(一些机器人检测只需检查 IP 地址使用量本身并忽略其他信誉标记),oxylabs 也提供的旋转 ISP 代理实际上可能更好。
6.使用随机延迟
这是 Realistic Page Flow 的一部分 – 但我把它作为一个单独的点,因为它也与不请求太多数据有关。
首先,让我们从页面流的角度来看它——人类和机器人的行为不同。您可以想象机器人往往比人类更快。没有真正的用户会在 5 秒内阅读一篇新闻文章。这就是为什么网站会跟踪您在网站上花费的时间、访问的页面数量等等的原因。
因此,只需在访问页面之间添加一些延迟。但也不要让它在每个页面上等待相同的时间,因为这也会被注意到。只需让您的机器人在站点上随机等待一段时间。
撇开这些不谈,让我们从“请求太多数据”的角度来看它——就像我在第三点中所说的那样。没有真正的用户会在 1 分钟内请求 1000 个站点。
因此,只需通过只允许它现实但足够快(这样你就不必等到太阳爆炸😉)它可以发出的请求数量来简单地限制你的机器人。
7. 不要使用无头浏览器
谁使用无头浏览器?绝对不是人类。这就是 Sites 开始测试浏览器是否为 Headless 的原因。
根据浏览器是否以无头模式运行,不同的功能可能可用也可能不可用。这就是可以检测浏览器是否以无头模式运行的原因。
大多数测试都是针对 Chrome 的,因为现在大多数机器人都使用 Chrome。这些测试旨在确定功能的行为是否与它们在常规 Chrome 中的行为相同,或者它们的行为是否与 Headless Chrome 中的行为相同。
通过检查权限 API 的行为可以在此处看到一个示例:
navigator.permissions.query({name:'notifications'}).then(function(permissionStatus) {
if(Notification.permission === 'denied' && permissionStatus.state === 'prompt') {
console.log("Headless Chrome");
} else {
console.log("Not Headless Chrome");
}
});在 Headless Chrome 中,测试返回没有意义的值。一方面,它说发送通知的权限是denied在使用Notification.permission. 另一方面,它prompt在使用时返回navigator.permissions.query。
有大量可用的测试,我在此处创建了一个GitHub 存储库和一篇关于进一步检测无头浏览器的方法的文章。
8. 验证码
验证码(或完全自动化的公开测试告诉计算机和人类**的一部分)是更难破解的反抓取措施之一,幸运的是验证码对真实用户来说也非常烦人**。
这意味着许多站点甚至不使用它们,并且在使用时通常仅限于某些形式。
但是,如果他们确实妨碍了您怎么办?
绕过验证码的第一步是按照此处列出的所有其他步骤并单击按钮 – 但如果失败并且您的“人性化分数”太低,您现在面临解决这些太熟悉的图片的问题拼图
前提是使用 Google reCAPTCHA V2、原始验证码或不是由 google 制作的类似变体。使用 Google reCAPTCHA V3,这些图片拼图不再存在,只会0.1 to 0.9根据用户进行的交互计算两者之间的分数。要绕过 reCAPTCHA V3,您“唯一”的解决方案是注意此处列出的其他要点或使用支持 reCAPTCHA V3 的验证码农场 – 您可以在此处查看您的 reCAPTCHA 分数。
破解验证码可以通过人工智能(计算机视觉/语音到文本)工具或农场\来完成,在农场中,真人会得到报酬为您解决验证码。这些服务甚至可用于最新的 Google 图像 reCAPTCHA,只是会产生额外费用。
验证码农场
CAPTCHA 农场基本上会接受你面临的 CAPTCHA 测试,将其发送给一个真正的人,然后由他完成它,然后将人为生成的正确答案发回给你,你现在可以用它来验证你的“人性”。
有许多服务可以为您解决验证码问题,然后收取少量费用——通常每 1000 个验证码向您收费。目前的正常费率是 0.5 美元到 3 美元,具体取决于验证码类型。一些常见的服务是2captcha、anti-captcha.com和deathbycaptcha。
在下面的示例中,我将使用 2captcha 来解决 Google reCAPTCHA V2,但在这里您还可以找到解决 reCAPTCHA V3的教程和这里的普通老式验证码教程(顺便说一句,我与 2captcha 无关所有,他们只是有大量不同验证码样式的教程)。
1.从验证码中获取站点密钥
这site key是每个站点在实施 reCAPTCHA V2 时获得的唯一密钥。您将使用此站点密钥将其发送到 2captcha。当您搜索验证码元素本身时,您会找到站点密钥,如下所示:
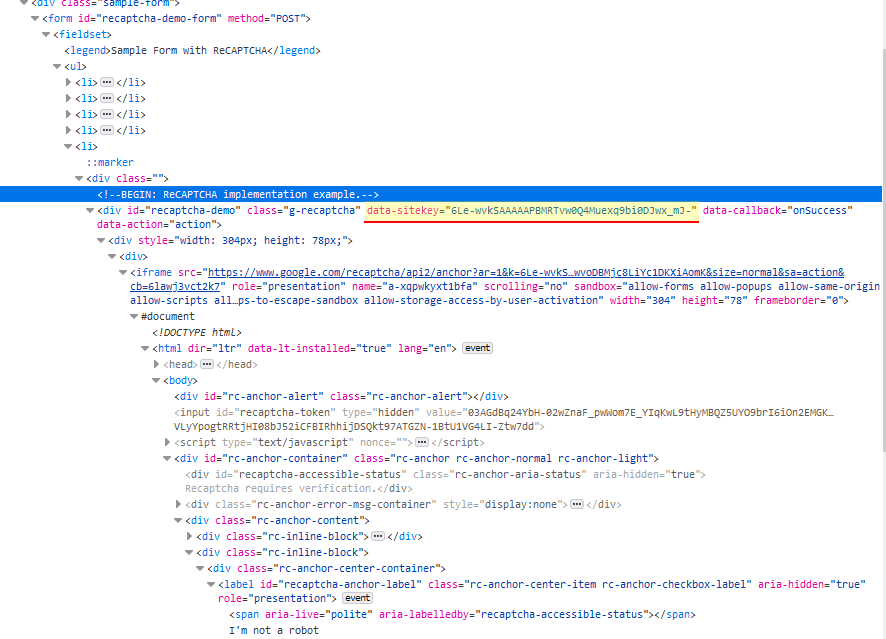
使用 beautifulsoup4 或类似的 HTML 解析器从元素中获取此键。
2.将站点密钥发送到2Captcha
现在您需要将您从第 1 步获得的站点密钥、您在注册时获得的 2Captcha API 密钥以及放置验证码的站点的 URL 发送到 2Captchas API。
请参阅此 Python 代码示例:
import requests
import time
from selenium import webdriver
siteKey = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-"
apiKey = "Place Your 2Captcha Site key here"
pageUrl = "https://google.com/recaptcha/api2/demo"
form = {"method": "userrecaptcha",
"googlekey": site_key,
"key": apiKey,
"pageurl": pageUrl,
"json": 1}
response = requests.post('http://2captcha.com/in.php', data=form)
requestId = response.json()['request']3.取回request ID并提交Form
url = f"http://2captcha.com/res.php?key={api_key}&action=get&id={request_id}&json=1"
status = 0
while not status:
res = requests.get(url)
if res.json()['status']==0:
# Response is not ready
time.sleep(3)
else:
# Response is ready
requ = res.json()['request']
# Open the Website with form using Selenium
driver = webdriver.Chrome(executable_path=r'.\chromedriver.exe')
driver.get(pageurl)
# Place the the request id received into the HTML of the Captcha
js = f'document.getElementById("g-recaptcha-response").innerHTML="{requ}";'
driver.execute_script(js)
# Click submit button
driver.find_element_by_id("recaptcha-demo-submit").submit()
status = 1
验证码人工智能
url = f"http://2captcha.com/res.php?key={api_key}&action=get&id={request_id}&json=1"
status = 0
while not status:
res = requests.get(url)
if res.json()['status']==0:
# Response is not ready
time.sleep(3)
else:
# Response is ready
requ = res.json()['request']
# Open the Website with form using Selenium
driver = webdriver.Chrome(executable_path=r'.\chromedriver.exe')
driver.get(pageurl)
# Place the the request id received into the HTML of the Captcha
js = f'document.getElementById("g-recaptcha-response").innerHTML="{requ}";'
driver.execute_script(js)
# Click submit button
driver.find_element_by_id("recaptcha-demo-submit").submit()
status = 1您可以编写自己的AI 来识别图像/AI 来识别语音,使用其他人的 AI并重新调整它的用途,或者您甚至可以使用一些 API 进行图像/音频识别,例如 Amazon 的 Transcribe Speech-to-Text API、PocketSphinx、Mozilla 的 DeepSpeech、Google语音或 Wit.AI。
但也有人已经编写了一个库来实现这些工具——其中之一是MacKey -255的GoodByeCaptcha 。
它使用FFmpeg(顺便说一下,很棒的工具)、Microsoft Azure、Amazons Transcribe、YolvoV3、Wit.AI 或 Pocketsphinx 来识别语音/图像并为您解决验证码——我不会向您展示如何将它实现到您的 python 中代码,作者在这里做了一个很好的文字教程或者一个很好的视频教程。
9. 拿着饼干
在某些情况下, 收集和保存 cookie可能是值得的。
大多数抓取的人不会通过使用隐身窗口和/或重新启动而不保留您的 cookie 来保留他们的 cookie。但这可能会引起某些网站的怀疑。
就像我上面已经说过的,网站可以在一个站点上设置 cookie 并检查它是否存在于另一个站点上。例如,他们可以通过这种方式跟踪您的页面流。
如果您不介意获得自定义结果,最好不要在每次发出新请求时都使用隐身模式/重新启动隐身模式,这样您就可以保留 cookie
有2 种保存 cookie 的好方法,对于大多数用例,我会推荐第二种方法,但也许你想尝试一下,所以我仍然会给你第一种方法 ^^
1. 使用 pickle 将当前的 cookies 保存为 Python 对象:
import pickle
from selenium import webdriver
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get("https://www.google.com")
pickle.dump(driver.get_cookies(), open("cookies.pkl","wb"))
import pickle
from selenium import webdriver
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get("https://www.google.com")
pickle.dump(driver.get_cookies(), open("cookies.pkl","wb"))稍后将它们添加回去:
import pickle
import selenium.webdriver
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get("http://www.google.com")
if os.path.isfile("cookies.pkl"):
cookies = pickle.load(open("cookies.pkl", "rb"))
for cookie in cookies:
driver.add_cookie(cookie)2. Chrome 选项 user-data-dir 以便将文件夹用作配置文件:
将此代码添加到您的 Bot 中,所有 cookie 将从现在开始出现(当然,减去 cookie 通常会因时间过期或因为它们仅在会话期间保留而过期。):
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("user-data-dir=selenium")
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get("https://www.google.com")优点是可以使用多个不同设置和cookies的文件夹,无需加载、卸载cookies、安装和卸载扩展程序、更改设置、通过代码更改登录,从而无法破坏程序逻辑等。
10. 后退
一些爬虫和爬虫努力做的是在开始服务时退避。403/503 errors通过简单地忽略这些消息并在收到这些错误后请求更多站点,很明显你真的是一个机器人而不是一个人 – 没有人会在收到错误后尝试重新加载页面 1000 次以停止尝试。
当您遇到错误时,只需放慢速度并后退,就可以帮助您避免损害您的 IP 声誉和禁止您自己。
只需对这些错误执行一个小检查,然后在重试之前停止程序/休眠一段时间。
11. Ultrafunkamsterdam 的 ChromeDriver
Ultrafunkamsterdam创建了一个ChromeDriver,它已经包含本文的第 1 点和第 2 点,以及许多其他功能。(我本来打算做一个类似这个的ChromeDriver,结果他先到了^^)
因为这个项目是开源的,它应该经常更新,让 chromedriver 保持不被发现。
它目前可以缓解所有主要的机器人检测系统,例如 Distil、Datadome、Cloudflare 等。随着这些供应商更新他们的系统,这在未来可能会改变,特别是因为他们可以访问这个 chromedriver 并且可能能够在某处找到识别它的东西。
但就目前而言,它是一个很棒的工具;你所要做的就是:
pip install undetected-chromedriver然后,就像使用常规硒一样,使用它:
import undetected_chromedriver.v2 as uc
options = uc.ChromeOptions()
# setting profile
options.user_data_dir = "c:\\temp\\profile"
# another way to set profile is the below (which takes precedence if both variants are used
options.add_argument('--user-data-dir=c:\\temp\\profile2')
# just some options passing in to skip annoying popups
options.add_argument('--no-first-run --no-service-autorun --password-store=basic')
driver = uc.Chrome(options=options)
with driver:
driver.get('https://nowsecure.nl') # known url using cloudflare's "under attack mode"专家提示
这个 chromedriver 不是隐藏所有机器人的灵丹妙药!
您仍然需要遵循本文中的其他提示,例如真实的页面流、更改您的 IP、不使用无头浏览器、保留 cookie、退出等等。
但是,如果您使用的是 Python,那么这是一个很好的起点,可以让您的机器人不被发现,至少在 chromedriver 技术站点上是这样。
12. 用户数据一致性
我已经在第 3 点提到了你的操作系统、浏览器等与你的用户代理和所有匹配方面的一致性。
然而,另一个需要一致性的关键点是使用用户帐户登录时。
在审查其他人的机器人时,我经常遇到这个问题。他们经常随机化他们的用户代理、IP 以及我之前提到的任何其他内容,但随后忘记了使用用户帐户登录时这没有任何意义。
例如,假设您有一个用户 A,他在第一次登录时使用的 IP 地址来自*德国,但是当您下次使用此帐户登录时,您随机分配了 IP/代理,他现在拥有一个*俄罗斯IP 地址。
这意味着用户只是在未登录的情况下前往另一个国家。这有时是合理的,但如果您随后将他的 IP 地址更改为阿根廷,则您的用户必须是一个非常频繁的旅行者才能实现这一点哈哈。
User Agent 也是如此;您不能简单地每 5 分钟更改一次他使用的浏览器和操作系统。特别是如果他曾经使用过 91 版 Chrome,然后在 5 分钟后使用了 89 版浏览器,然后是 90 版,然后又是 91 版,依此类推……
这意味着他不断地降级和升级他的浏览器。
这根本不是现实的行为。
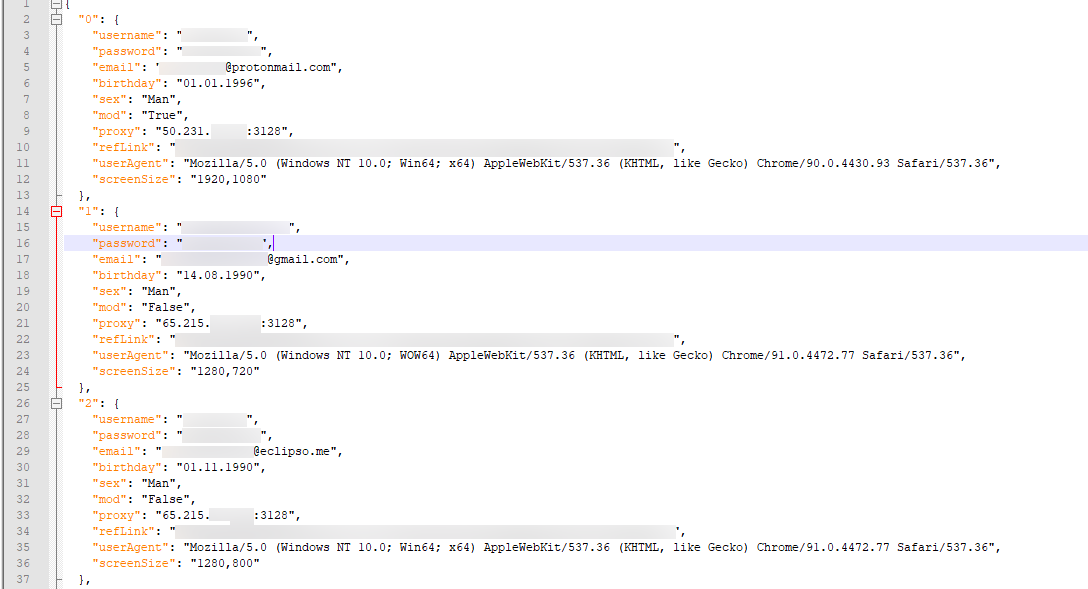
因此,简而言之,如果您仍然不明白我的意思:维护一个包含用户名、密码、**用户代理、IP 地址等的文本文件**(或 json、数据库或其他)。然后,无论何时以该用户身份登录,您都应该始终使用该数据。
上面是一个示例 Json 文件的屏幕截图,一些细节被模糊了。
结论
在防止 Bot 检测方面,没有灵丹妙药。每种技术都有其优点和缺点。
随着时间的推移,我所说的一些策略可能会被网站所有者考虑,然后会发现隐藏它们的新技术。这是一场永无止境的猫捉老鼠游戏。
但就目前而言,这些可能是隐藏您的 (Selenium) Bot 不被发现的最佳方法。


最新评论
非常好.去中國出差時就能正常使用手機了.感謝
搭好后 防火墙就自动关了,请问有没有办法让防火墙开起的情况下,比如添加端口,让梯子能用?
感谢,一次搞定
作者写的就是只能命令行访问,在GUI界面 注册表查询依旧没有走代理。
这个跟bandwagon的一样吗 也是能用v2ray吗
一步步来的,就是不行。